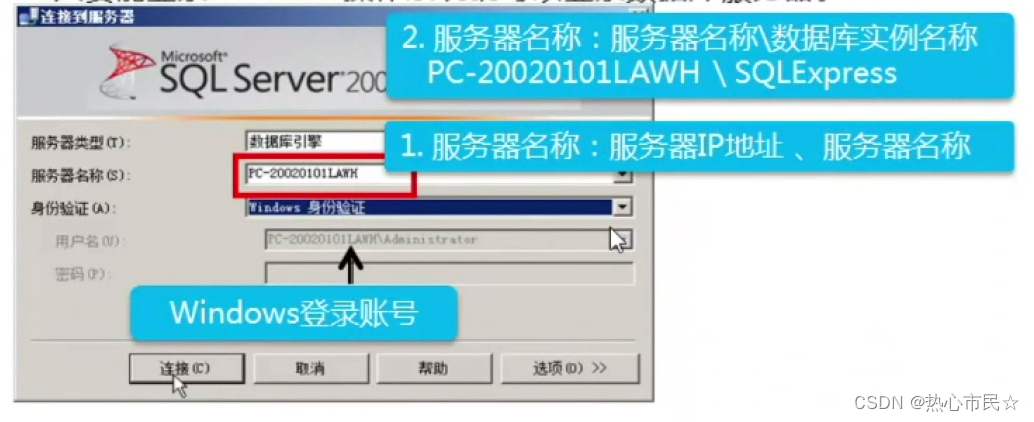
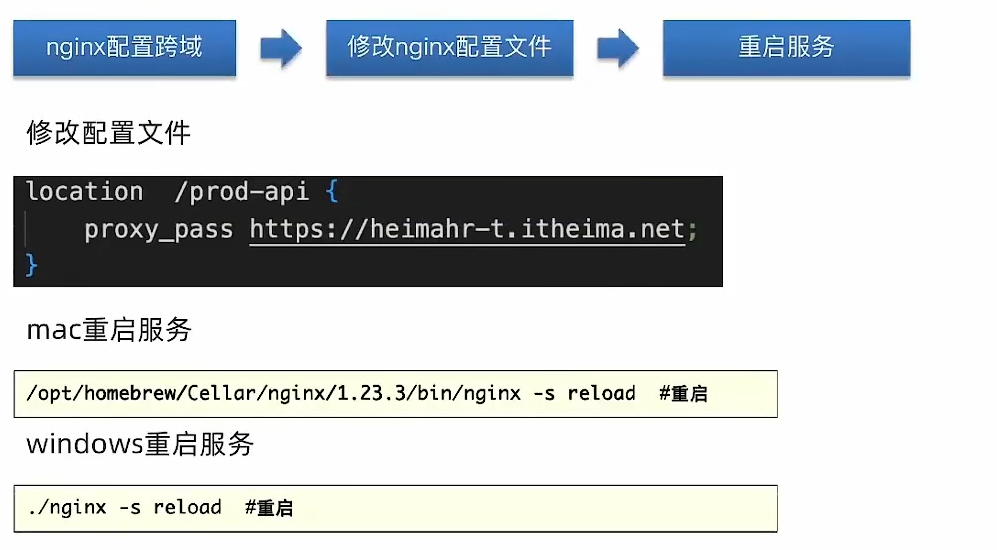
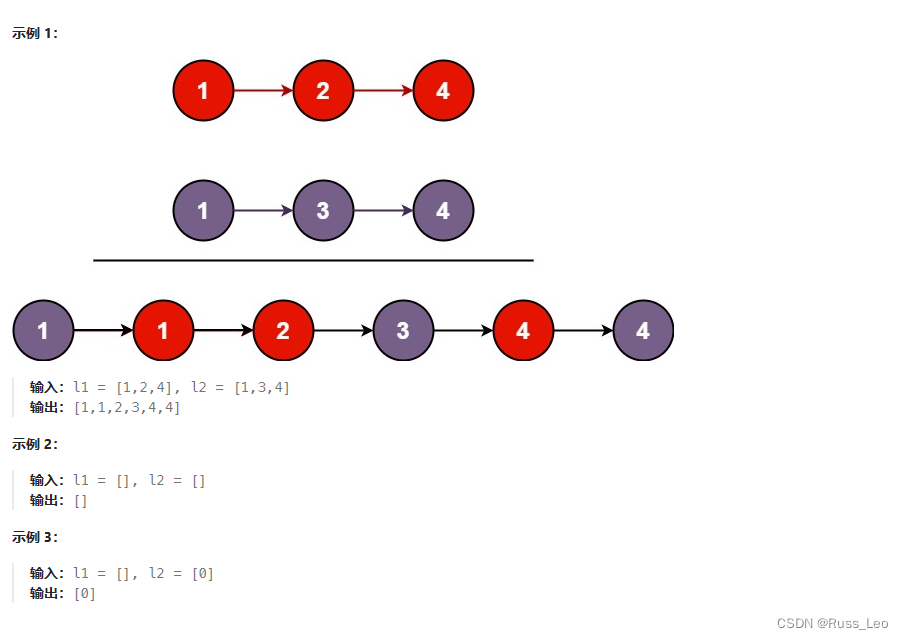
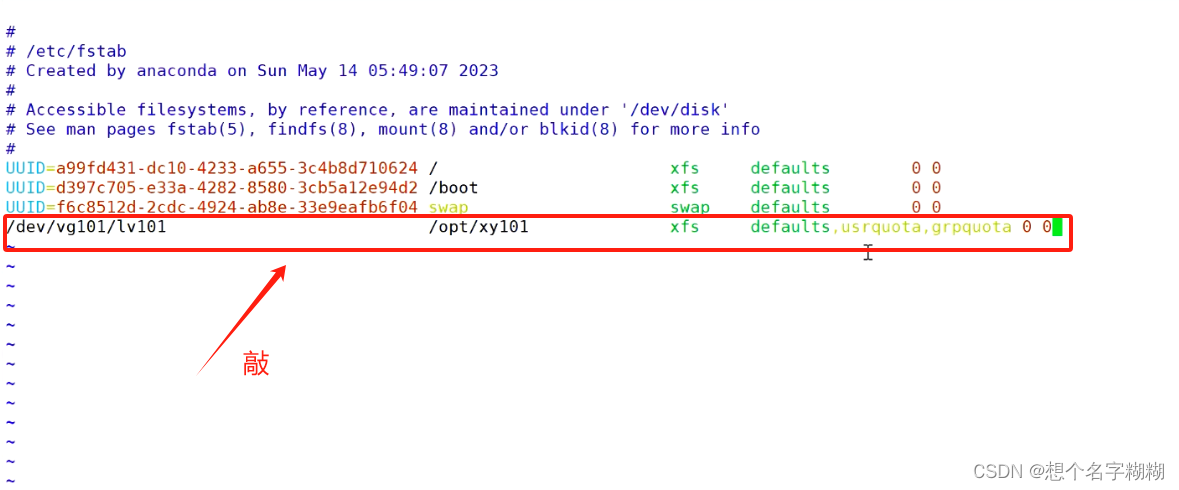
next_siblings() 是一个 BeautifulSoup 库中的函数,用于在 HTML 或 XML 文档中查找当前节点之后的所有兄弟节点。它返回一个生成器对象,可以用于迭代获取当前节点之后的所有兄弟节点。
例如,如果你有一个 HTML 文档结构如下:
<html>
<body>
<div class="container">
<p>Paragraph 1</p>
<p>Paragraph 2</p>
<p>Paragraph 3</p>
</div>
</body>
</html>
如果你想要获取第一个 <p> 标签后的所有兄弟节点,你可以使用 next_siblings() 函数,如下所示:
from bs4 import BeautifulSoup
html = """
<html>
<body>
<div class="container">
<p>Paragraph 1</p>
<p>Paragraph 2</p>
<p>Paragraph 3</p>
</div>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
first_paragraph = soup.find('p') # 找到第一个 <p> 标签
siblings = first_paragraph.next_siblings # 获取第一个 <p> 标签后的所有兄弟节点
for sibling in siblings:
print(sibling)
这将打印出第一个 <p> 标签后的所有兄弟节点,即第二个和第三个 <p> 标签。
这个函数对于在解析 HTML 或 XML 文档时查找特定节点之后的相关内容非常有用。